This problem has been cracked (but not quite completely solved) by Alina, Pradeep, and I. The problem is essentially finding a better way to reduce multiclass classification to binary classification. The solution is to use a carefully crafted tournament, the simplest version of which is a single elimination tournament where the “players” are the different classes. An example of the structure is here:
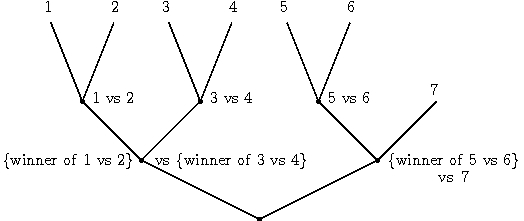
For the single elimination tournament, we can prove that:
Here:
- Filter_tree_train(D) is the induced binary classification problem
- Filter_tree_test(c) is the induced multiclass classifier.
- regmulticlass is the multiclass regret (= difference between error rate and minimum possible error rate)
- regbinary is the binary regret
This result has a slight dependence on k which we suspect is removable. The current conjecture is that this dependence can be removed by using higher order tournaments such as double elimination, triple elimination, up to log2 k-elimination.
The key insight which makes the result possible is conditionally defining the prediction problems at interior nodes. In essence, we use the learned classifiers from the first level of the tree to filter the distribution over examples reaching the second level of the tree. This process repeats, until the root node is reached. Further details, including a more precise description and some experimental results are in the draft paper.
Voila!
This paper will make a great anonymous submission!
These two papers might be related:
Lin Dong, Eibe Frank, and Stefan Kramer. Ensembles of balanced nested dichotomies for multi-class problems. In Proc 9th European Conference on Principles and Practice of Knowledge Discovery in Databases, Porto, Portugal, pages 84-95. Springer, 2005.
Eibe Frank and Stefan Kramer. Ensembles of nested dichotomies for multi-class problems. In Proc 21st International Conference on Machine Learning, Banff, Canada, pages 305-312. ACM Press, 2004.
I think blogs are in many ways a better way of doing peer review than conferences.
Thanks a lot, I wasn’t aware of this.
I didn’t find the second paper online, but the first is. A major difference to me is that the first paper doesn’t do conditional training. Instead, they estimate the probability of label membership in subsets. I’m not sure, but I expect they multiply these predicted probabilities on a path from root to label in order to estimate the probability some label is correct, then average over a number of different splits of trees. This scheme isn’t as robust to prediction failures (and relies on a stronger primitive). I suspect you could prove something like: multiclass regret is bounded by sqrt( k * squared error regret) for it. Another difference is that this one requires evaluation of k class probability predictors while you can hope to get away with only log k evalutions for these tournaments.
Adding an ensemble varying over the class pairings would probably improve our empirical results, just as it did theirs.
I detect a tense failure: will vs. was. 🙂
In any case, it’s already been discussed publicly.
I was wondering if you could say what relationship, if any, regret has with the bias-variance decomposition of loss? I ask because you say in the paper that it aims to “separate avoidable loss from loss inherent in the problem”. Doesn’t the noise term in BV-decomposition cover the inherent loss?
This is also somewhat related in case you haven’t seen it: http://ssli.ee.washington.edu/people/bilmes/mypapers/nips01.pdf
The authors also use a tournament of binary classifiers, although it is also missing the conditional training (and the regret analysis).
Do you have a pointer to the precise formulation you are thinking about? I normally think about loss in terms of overfitting (~= variance), model misspecification (~= bias), and unremovable noise. Regret subtracts off the unremovable noise.
I was thinking of bias-variance as described in Domingos’ paper A Unified Bias-Variance Decomposition and its Applications.
Re-reading the relevant parts of both papers, I think the relationship I originally thought was there isn’t all that important. Regret seems to be a classifier-specific measure (i.e., the difference between the expected 0-1 loss of this classifier and the best one w.r.t. P) whereas the average bias and average variance definitions are concerned with expected loss of classifiers produced by a learner taken over all training and tests sets. The noise here is just the Bayes rate.