I just created Vowpal Wabbit 7.8, and we are planning to have an increasingly less heretical followup tutorial during the non-“ski break” at the NIPS Optimization workshop. Please join us if interested.
I always feel like things are going slow, but in the last year, but there have been many changes overall. Notes for 7.7 are here. Since then, there are several areas of improvement as well as generalized bug fixes and refactoring.
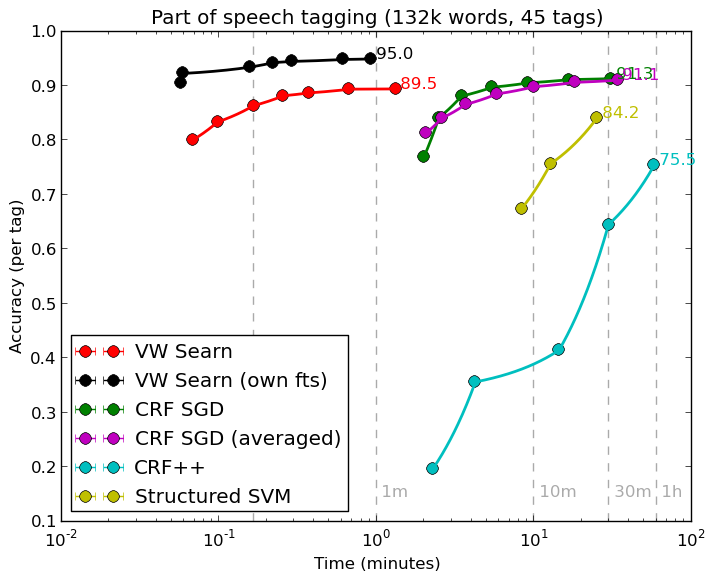
- Learning to Search: Hal completely rewrote the learning to search system, enough that the numbers here are looking obsolete. Kai-Wei has also created several advanced applications for entity-relation and dependency parsing which are promising.
- Languages Hal also created a good python library, which includes call-backs for learning to search. You can now develop advanced structured prediction solutions in a nice language. Jonathan Morra also contributed an initial Java interface.
- Exploration The contextual bandit subsystem now allows evaluation of an arbitrary policy, and an exploration library is now factored out into an independent library (principally by Luong with help from Sid and Sarah). This is critical for real applications because randomization must happen at the point of decision.
- Reductions The learning reductions subsystem has continued to mature, although the perfectionist in me is still dissatisfied. As a consequence, it’s now pretty easy to program new reductions, and the efficiency of these reductions has generally improved. Several news ones are cooking.
- Online Learning Alekh added an online SVM implementation based on LaSVM. This is known to parallelize well via the para-active approach.
This project has grown quite a bit—there are about 30 different people contributing to VW since the last release, and there is now a VW meetup (December 8th!) in the bay area that I wish I could attend.