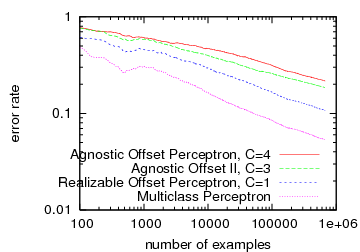
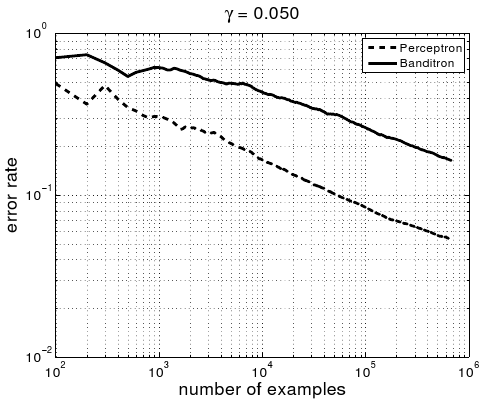
Few would mistake the process of academic paper review for a fair process, but sometimes the unfairness seems particularly striking. This is most easily seen by comparison:
| Paper | Banditron | Offset Tree | Notes |
| Problem Scope | Multiclass problems where only the loss of one choice can be probed. | Strictly greater: Cost sensitive multiclass problems where only the loss of one choice can be probed. | Often generalizations don’t matter. That’s not the case here, since every plausible application I’ve thought of involves loss functions substantially different from 0/1. |
| What’s new | Analysis and Experiments | Algorithm, Analysis, and Experiments | As far as I know, the essence of the more general problem was first stated and analyzed with the EXP4 algorithm (page 16) (1998). It’s also the time horizon 1 simplification of the Reinforcement Learning setting for the random trajectory method (page 15) (2002). The Banditron algorithm itself is functionally identical to One-Step RL with Traces (page 122) (2003) in Bianca‘s thesis with the epsilon greedy strategy and a multiclass perceptron with update scaled by the importance weight. |
| Computational Time | O(k) per example where k is the number of choices | O(log k) per example | Lower bounds on the sample complexity of learning in this setting are a factor of k worse than for supervised learning, implying that many more examples may be needed in practice. Consequently, learning algorithm speed is more important than in standard supervised learning. |
| Analysis | Incomparable. An online regret analysis showing that if a small hinge loss predictor exists, a bounded number of mistakes occur. Also, an algorithm independent analysis of the fully realizable case. | Incomparable. A learning reduction analysis showing how the regret of any base classifier bounds policy regret. Also contains a lower bound and comparable analysis of all plausible alternative reductions. | |
| Experiments | 1 dataset, comparing with no other approaches to solving the problem. | 13 datasets, comparing with 2 other approaches to solve the problem. | |
| Outcome | Accepted at ICML | Rejected at ICML, NIPS, UAI, and NIPS. |
The reviewers of the Banditron paper made the right call. The subject is interesting, and analysis of a new learning domain is of substantial interest. Real advances in machine learning often come as new domains of application. The talk was well attended and generated substantial interest. It’s also important to remember the reviewers of the two papers probably did not overlap, so there was no explicit preference for A over B.
Why was the Offset Tree rejected? One of these rejections is easily explained as a fluke—we ran into a reviewer at UAI who believes that learning by memorization is the way to go. I, and virtually all machine learning people, disagree but some reviewers at UAI aren’t interested or expert in machine learning.
The striking thing about the other 3 rejects is that they all contain a reviewer who doesn’t read the paper. Instead, the reviewer asserts that learning reductions are bogus because for an alternative notion of learning reduction, made up by the reviewer, an obviously useless approach yields a factor of 2 regret bound. I believe this is the same reviewer each time, because the alternative theorem statement drifted over the reviews fixing bugs we pointed out in the author response.
The first time we encountered this review, we assumed the reviewer was just cranky that day—maybe we weren’t quite clear enough in explaining everything as it’s always difficult to get every detail clear in new subject matter. I have sometimes had a very strong negative impression of a paper which later turned out to be unjustified upon further consideration. Sometimes when a reviewer is cranky, they change their mind after the authors respond, or perhaps later, or perhaps never but you get a new set of reviewers the next time.
The second time the review came up, we knew there was a problem. If we are generous to the reviewer, and taking into account the fact that learning reduction analysis is a relatively new form of analysis, the fear that because an alternative notion of reduction is vacuous our notion of reduction might also be vacuous isn’t too outlandish. Fortunately, there is a way to completely address that—we added an algorithm independent lower bound to the draft (which was the only significant change in content over the submissions). This lower bound conclusively proves that our notion of learning reduction is not vacuous as is the reviewer’s notion of learning reduction.
The review came up a third time. Despite pointing out the lower bound quite explicitly, the reviewer simply ignored it. This more-or-less confirms our worst fears. Some reviewer is bidding for the paper with the intent to torpedo review it. They are uninterested in and unwiling to read the content itself.
Shouldn’t author feedback address this? Not if the reviewer ignores it.
Shouldn’t Double Blind reviewing help? Not if the paper only has one plausible source. The general problem area and method of analysis were freely discussed on hunch.net. We withheld public discussion of the algorithm itself for much of the time (except for a talk at CMU) out of respect for the review process.
Why doesn’t the area chair/program chair catch it? It took us 3 interactions to get it, so it seems unrealistic to expect someone else to get it in one interaction. In general, these people are strongly overloaded and the reviewer wasn’t kind enough to boil down the essence of the stated objection as I’ve done above. Instead, they phrase it as an example and do not clearly state the theorem they have in mind or distinguish the fact that the quantification of that theorem differs from the quantification of our theorems. More generally, my observation is that area chairs rarely override negative reviews because:
- It risks their reputation since defending a criticized work requires the kind of confidence that can only be inspired by a thorough personal review they don’t have time for.
- They may offend the reviewer they invited to review and personally know.
- They figure that the average review is similar to the average perception/popularity by the community anyways.
- Even if they don’t agree with the reviewer, it’s hard to fully discount the review in their consideration.
I’ve seen these effects create substantial mental gymnastics elsewhere.
Maybe you just ran into a cranky reviewer 3 times randomly Maybe so. However, the odds seem low enough and the 1/2 year cost of getting another sample high enough, that going with the working hypothesis seems indicated.
Maybe the writing needs improving. Often that’s a reasonable answer for a rejection, but in this case I believe not. We’ve run the paper by several people, who did not have substantial difficulties understanding it. They even understand the draft well enough to make a suggestion or two. More generally, no paper is harder to read than the one you picked because you want to reject it.
What happens next? With respect to the Offset Tree, I’m hopeful that we eventually find reviewers who appreciate an exponentially faster algorithm, good empirical results, or the very tight and elegant analysis, or even all three. For the record, I consider the Offset Tree a great paper. It remains a substantial advance on the state of the art, even 2 years later, and as far as I know the Offset Tree (or the Realizable Offset Tree) consistently beat all reasonable contenders both in prediction and computational performance. This is rare and precious, as many papers tradeoff one for the other. It yields a practical algorithm applicable to real problems. It substantially addresses the RL to classification reduction problem. It also has the first nonconstant algorithm independent lower bound for learning reductions.
With respect to the reviewer, I expect remarkably little. The system is designed to protect reviewers, so they have virtually no responsibility for their decisions. This reviewer has a demonstrated capability to sabotage the review process at ICML and NIPS and a demonstrated willingness to continue doing so indefinitely. The process of bidding for papers and making up reasons to reject them seems tedious, but there is no fundamental reason why they can’t continue doing so for several decades if they remain active in academia.
This experience has substantially altered my understanding and appreciation of the review process at conferences. The bidding mechanism commonly used, coupled with responsibility-free reviewing is an invitation to abuse. A clever abusive reviewer can sabotage perhaps 5 papers per conference (out of 8 reviewed), while maintaining a typical average score. While I don’t believe most people choose papers with intent to sabotage, the capability is there and used by at least one person and possibly others. If, for example, 5% of reviewers are willing to abuse the process this way and there are 100 reviewers, every paper must survive 5 vetoes. If there are 200 reviewers, every paper must survive 10 vetoes. And if there are 400 reviewers, every paper must survive 20 vetoes. This makes publishing any paper that offends someone difficult. The surviving papers are typically inoffensive or part of a fad strong enough that vetoes are held back. Neither category is representative of high quality decision making. These observations suggest that the conference with the most reviewers tend strongly toward faddy and inoffensive papers, both of which often lack impact in the long term. Perhaps this partly explains why NIPS is so weak when people start citation counting. Conversely, this would suggest that smaller conferences and workshops have a natural advantage. Similarly, the reviewing style in theory conferences seems better—the set of bidders for any paper is substantially smaller, implying papers must survive fewer vetos.
This decision making process can be modeled as a group of n decision makers, each of which has the opportunity to veto any action. When n is relatively small, this decision making process might work ok, depending on the decision makers, but as n grows larger, it’s difficult to imagine a worse decision making process. The closest representatives outside of academia I know are deeply bureacratic governments and other large organizations where many people must sign off on something before it takes place. These vetocracies are universally frustrating to interact with. A reasonable conjecture is that any decision making process with a large veto number has poor characteristics.
A basic question is: Is a vetocracy inevitable for large organizations? I believe the answer is no. The basic observation is that the value of n can be logarithmic in the number of participants in an organization rather than linear, as per reviewing under a bidding process. An essential force driving vetocracy creation is a desire to offload responsibility for decisions, so there is no clear decision maker. A large organization not deciding by vetocracy must have a very different structure, with clearly dilineated responsibility.
NIPS provides an almost perfect natural experiment in it’s workshop organization, which involves the very same community of people and subject matter, yet works in a very different manner. There are one or two workshop chairs who are responsible for selecting amongst workshop proposals, after which the content of the workshop is entirely up to the workshop organizers. If a workshop is rejected, it’s clear who is at fault, and if a workshop presentation is rejected, it is often clear by who. Some workshop chairs use a small set of reviewers, but even then the effective veto number remains small. Similarly, if a workshop ends up a flop, it’s relatively easy to see who to blame—either the workshop chair for not predicting it, or the organizers for failing to organize. I can’t think of a single time when I attended both the workshops and the conference that the workshops were less interesting than the conference. My understanding is that this observation is common. Given this discussion, it will be particularly interesting to see how the review process Michael and Leon setup for ICML this year pans out, as it is a system with notably more responsibility assignment than in previous years.
Journals end up looking relatively good with respect to vetocracy avoidance. The ones I’m familiar with have a chief editor who bears responsibility for routing papers to an action editor, who bears responsibility for choosing good reviewers. Every agent except the reviewers is often known by the authors, and the reviewers don’t act as additional vetoers in nearly as strong a manner as reviewers with the opportunity to bid.
This experience has also altered my view of blogging and research. On one hand, I’m very enthusiastic about research in general, and my research in particular, where we are regularly cracking conventionally impossible problems. On the other hand, it seems that some small number of people viewing a discussion silently decide they don’t like it, and veto it given the opportunity. It only takes one to turn strong paper into a years-long odyssey, so public discussion of research directions and topics in a vetocracy is akin to voluntarily wearing a “kick me” sign. While this a problem for me, I expect it to be even worse for the members of a vetocracy in the long term.
It’s hard to imagine any research community surviving without a serious online presence. When a prospective new researcher looks around at existing research, if they don’t find serious online discussion, they’ll assume it doesn’t exist under the “not on the internet so it doesn’t exist” principle. This will starve a field of new people. More generally, there is an opportunity to get feedback about research directions and problems much more rapidly than is otherwise possible, allowing us to avoid research on dead end topics which are pervasive. At some point, it may even seem that people not willing to discuss their research simply avoid doing so because it is critically lacking in one way or another. Since a vetocracy creates a substantial disincentive to discuss research directions online, we can expect that communities sticking with decision by vetocracy to be at a substantial disadvantage.