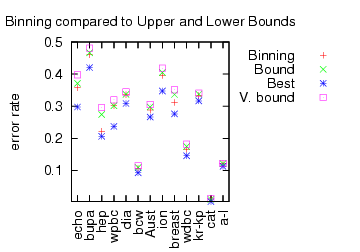
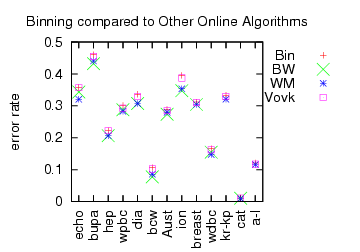
There are a number of learning algorithms which explicitly incorporate randomness into their execution. This includes at amongst others:
- Neural Networks. Neural networks use randomization to assign initial weights.
- Boltzmann Machines/Deep Belief Networks. Boltzmann machines are something like a stochastic version of multinode logistic regression. The use of randomness is more essential in Boltzmann machines, because the predicted value at test time also uses randomness.
- Bagging. Bagging is a process where a learning algorithm is run several different times on several different datasets, creating a final predictor which makes a majority vote.
- Policy descent. Several algorithms in reinforcement learning such as Conservative Policy Iteration use random bits to create stochastic policies.
- Experts algorithms. Randomized weighted majority use random bits as a part of the prediction process to achieve better theoretical guarantees.
A basic question is: “Should there be explicit randomization in learning algorithms?” It seems perverse to feed extra random bits into your prediction process since they don’t contain any information about the problem itself. Can we avoid using random numbers? This question is not just philosophy—we might hope that deterministic version of learning algorithms are both more accurate and faster.
There seem to be several distinct uses for randomization.
- Symmetry breaking. In the case of a neural network, if every weight started as 0, the gradient of the loss with respect to every weight would be the same, implying that after updating, all weights remain the same. Using random numbers to initialize weights breaks this symmetry. It is easy to believe that there are good deterministic methods for symmetry breaking.
- Overfit avoidance. A basic observation is that deterministic learning algorithms tend to overfit. Bagging avoids this by randomizing the input of these learning algorithms in the hope that directions of overfit for individual predictions cancel out. Similarly, using random bits internally as in a deep belief network avoids overfitting by forcing the algorithm to learn a robust-to-noise set of internal weights, which are then robust-to-overfit. Large margin learning algorithms and maximum entropy learning algorithms can be understood as deterministic operations attempting to achieve the same goal. A significant gap remains between randomized and deterministic learning algorithms: the deterministic versions just deal with linear predictions while the randomized techniques seem to yield improvements in general.
- Continuizing. In reinforcement learning, it’s hard to optimize a policy over multiple timesteps because the optimal decision at timestep 2 is dependent on the decision at timestep 1 and vice versa. Randomized interpolation of policies offers a method to remove this cyclic dependency. PSDP can be understood as a derandomization of CPI which trades off increased computation (learning a new predictor for each timestep individually). Whether or not we can avoid a tradeoff in general is unclear.
- Adversary defeating. Some algorithms, such as randomized weighted majority are designed to work against adversaries who know your algorithm, except for random bits. The randomization here is provably essential, but the setting is often far more adversarial than the real world.
The current state-of-the-art is that random bits provide performance (computational and predictive) which we don’t know (or at least can’t prove we know) how to achieve without randomization. Can randomization be removed or is it essential to good learning algorithms?