Disclaimer: I am not an epidemiologist, but there is an interesting potentially important pattern in the data that seems worth understanding.
World healthcare authorities appear to be primarily shifting towards Social Distancing. However, there is potential to pursue a different strategy in the medium term that exploits a vulnerability of this disease: the 5 day incubation time is much longer than a 4 hour detection time. This vulnerability is real—it has proved exploitable at scale in South Korea and in China outside of Hubei.
Exploiting this vulnerability requires:
- A sufficient capacity of rapid tests be available. Sufficient here is perhaps 30 times the number of true new cases per day based on South Korea’s testing rate.
- The capacity to rapidly trace the contacts of confirmed positive cases. This is both highly labor intensive and absurdly cheap compared to shutting down the economy.
- Effective quarantining of positive and suspect cases. This could be in home, with the quarantine extended to the entire family. It could also be done in a hotel (… which are pretty empty these days), or in a hospital.
Where Test/Trace/Quarantine are working, the number of cases/day have declined empirically. Furthermore, this appears to be a radically superior strategy where it can be deployed. I’ll review the evidence, discuss the other strategies and their consequences, and then discuss what can be done.
Evidence for Test/Trace/Quarantine
The TTQ strategy works when it effectively catches a 1 – 1 / reproduction number fraction of cases. The reproduction number is not precisely known although discovering 90% of cases seems likely effective and 50% of cases seems likely ineffective based on public data.
How do you know what fraction of cases are detected? A crude measure can be formed by comparing detected cases / mortality across different countries. Anyone who dies from pneumonia these days should be tested for COVID-19 so the number of deaths is a relatively trustworthy statistic. If we suppose the ratio of true cases to mortality is fixed, then the ratio of observed cases to mortality allows us to estimate the fraction of detected cases. For example, if the true ratio between infections and fatalities is 100 while we observe 30, then the detection rate is 30%.
There are many caveats to this analysis (see below). Nevertheless, this ratio seems to provide real information which is useful in thinking about the future. Drawing data from the Johns Hopkins COVID-19 time series, and plotting we see:
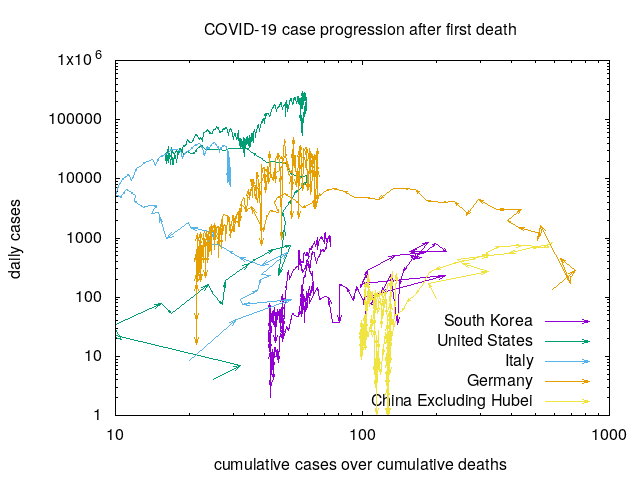
The arrows here represent the progression of time by days with time starting at the first recorded death. The X axis here is the ratio between cumulative observed cases and cumulative observed deaths. Countries that are able and willing to test widely have progressions on the right while those that are unable or unwilling to test widely are on the left. Note here that the X axis is on a log scale allowing us to see small variations in the ratio when the ratio is small and large variations in the ratio when the ratio is large.
The Y axis here is the number of cases/day. For a country to engage in effective Test/Trace/Quarantine, it must effectively test, which the X axis is measuring. Intuitively, we expect countries that test effectively to follow up with Trace and Quarantine, and we expect this to result in a reduced number of cases per day. This is exactly what is observed. Note that we again use a log scale for the Y axis due to the enormous differences in numbers.
There are several things you can read from this graph that make sense when you consider the dynamics.
- China excluding Hubei and South Korea had outbreaks which did not exceed the hospital capacity since the arrows start moving up and then loop back down around a 1% fatality rate.
- The United States has a growing outbreak and a growing testing capacity. Comparing with China-excluding-Hubei and South Korea’s outbreak, only a 1/4-1/10th fraction of the cases are likely detected. Can the United States expand capacity fast enough to keep up with the growth of the epidemic?
- Looking at Italy, you can see evidence of an overwhelmed healthcare system as the fatality rate escalates. There is also some hope here, since the effects of the Italian lockdown are possibly starting to show in the new daily cases.
- Germany is a strange case with an extremely large ratio. It looks like there is evidence that Germany is starting to control their outbreak, which is hopeful and aligned with our expectations.
The creation of this graph is fully automated and it’s easy to graph things for any country in the Johns Hopkins dataset. I created a github repository with the code. Feel free to make fun of me for using C++ as a scripting language 🙂
You can also understand some of the limitations of this graph by thinking through the statistics and generation process.
- Mortality is a delayed statistic. Apparently, it’s about a week delayed in the case of COVID-19. Given this, you expect to see the ratio generate loops when an outbreak occurs and then is controlled. South Korea and China-excluding-Hubei show this looping structure, returning to a ratio of near 100.
- Mortality is a small statistic, and a small statistic in the denominator can make the ratio unstable. When mortality is relatively low, we expect to see quite a variation. Checking each progression, you see wide ratio variations initially, particularly in the case of the United States.
- Mortality may vary from population to population. It’s almost surely dependent on the age distribution and health characteristics of the population and possibly other factors as well. Germany’s ratio is notably large here.
- Mortality is not a fixed variable, but rather dependent on the quality of care. A reasonable approximation of this is that every “critical” case dies without intensive care support. Hence, we definitely do not expect this statistic to hold up when/where the healthcare system is overwhelmed, as it is in Italy. This is also the reason why I excluded Hubei from the China data.
Lockdown
The only other strategy known to work is a “lockdown” where nearly everyone stays home nearly all the time, as first used in Hubei. This characterization is simplistic—in practice such a quarantine comes with many other measures as well. This can work very effectively—today the number of new case in Hubei is in the 10s.
The lockdown approach shuts down the economy fast and hard. Most people can’t work, so they can’t make money, so they can’t buy things, so the people who make things can’t make money, so they go broke, etc… This is strongly reflected in the stock market’s reaction to the escalating pandemic. If the lockdown approach is used for long most people and companies are destined for bankruptcy. If a lockdown approach costs 50% of GDP then a Test/Trace/Quarantine approach costing only a few% of GDP seems incredibly cheap in comparison.
The lockdown approach is also extremely intrusive. It’s akin to collective punishment in that it harms the welfare of everyone, regardless of their disease status. Many peoples daily lives fundamentally depend on moving around—for example people using dialysis.
Despite this, the lockdown approach is being taken up everywhere that cases are overwhelming or threaten to overwhelm hospitals because the alternative (next) is even worse. One advantage that a lockdown approach has is that it can be used now while the Test/Trace/Quarantine approach requires more organizing. It’s the best bad option when the Test/Trace/Quarantine capacity is exceeded or to bridge the time until it becomes available.
If/when/where Test/Trace/Quarantine becomes available, I expect it to be rapidly adopted. This new study (page 11) points out that repeated lockdowns are close to permanent lockdowns in effect.
Herd Immunity
Some countries have considered skipping measures to control the virus on the theory that the population eventually acquires enough people with individual immunity after recovery so the disease dies out. This approach invites severe consequences.
A key issue here is: How bad is the virus? The mortality rate in China excluding Hubei and South Korea is only about 1%. From this, some people appear to erroneously reason that the impact of the virus is “only” having 1% of 50% of the population die, heavily weighted towards older people. This reasoning is fundamentally flawed.
The mortality rate is not a fixed number, but rather dependent on the quality of care. In particular, because most countries have very few intensive care units, an uncontrolled epidemic effectively implies all but a vanishing fraction of sick people only benefit from home stay quality of care. How many people could die with home stay quality of care? Essentially everyone who would otherwise require intensive care at a hospital. In China, that meant 6.1% (see page 12). Given this, the sound understanding is that COVID-19 generates a factor 2-3 worse mortality than the 1918 influenza pandemic where modern healthcare might make this instead be half as bad when not overwhelmed. Note here that the fatality rate in Hubei (4.6% of known cases, which might be 3% of total cases) does not fully express how bad this would be due to the fraction of infected people remaining low and a surge of healthcare support from the rest of China.
The herd immunity approach also does not cause the disease to die out—instead it continues to linger in the population for a long time. This means that people traveling from such a country will be effectively ostracized by every country (like China or South Korea) which has effectively implemented a Test/Trace/Quarantine approach.
I’ve avoided discussing the ethics here since people making this kind of argument may not care about ethics. For everyone else it’s fair to say that letting part of the population die to keep the economy going is anathema. My overall expectation is that governments pursuing this approach are at serious risk of revolt.
Vaccine
Vaccines are extremely attractive because they are a very low cost way to end the pandemic. They are however uncertain and take time to develop and test, so they are not a viable strategy for the next few months.
What can be done?
Public health authorities are generally talking about Social Distancing. This is plausibly the best general-public message because everyone can do something to help here.
It’s also clear that healthcare workers, vaccines makers, and everyone supporting them have a critical role to play.
But, perhaps there’s a third group that can really help? Perhaps there are people who can help scale up the Test/Trace/Quarantine approach so it can be rapidly adopted? Natural questions here are:
- How can testing be scaled up rapidly—more rapidly than the disease? This question is already getting quite a bit of attention, and deservedly so.
- How can tracing be scaled up rapidly and efficiently? Hiring many people who are freshly out of work is the most obvious solution. That could make good sense given the situation. However, automated or partially automated approaches have the potential to greatly assist as well. I hesitate to mention cell phone tracking because of the potential for abuse, but can that be avoided while still gaining the potential public health benefits?
- How can quarantining be made highly precise and effective? Can you estimate the risk of infection with high precision? What support can safely be put in place to help those who are quarantined? Can we avoid the situation where the government says “you should quarantine” and “people in quarantine can’t vote”?
Some countries started this pandemic setup for relatively quick scaleup of the Test/Trace/Quarantine. Others, including the United States, seem to have been unprepared. Nevertheless, I am still holding out hope that the worst case scenarios (high mortality or months-long lockdowns) can be largely avoided as the available evidence suggests that this is certainly possible. Can we manage to get the number of true cases down (via a short lockdown if necessary) to the point where an escalating Test/Trace/Quarantine approach can take over?
Edit: I found myself remaking the graph for myself personally so I made it update hourly and added New York (where I live).