Online learning is in vogue, which means we should expect to see in the near future:
- Online boosting.
- Online decision trees.
- Online SVMs. (actually, we’ve already seen)
- Online deep learning.
- Online parallel learning.
- etc…
There are three fundamental drivers of this trend.
- Increasing size of datasets makes online algorithms attractive.
- Online learning can simply be more efficient than batch learning. Here is a picture from a class on online learning:
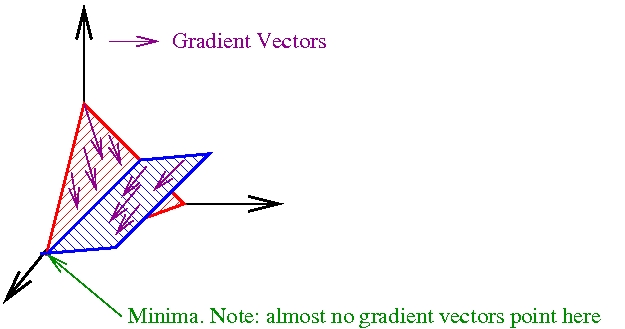
The point of this picture is that even in 3 dimensions and even with linear constraints, finding the minima of a set in an online fashion can be typically faster than finding the minima in a batch fashion. To see this, note that there is a minimal number of gradient updates (i.e. 2) required in order to reach the minima in the typical case. Given this, it’s best to do these updates as quickly as possible, which implies doing the first update online (i.e. before seeing all the examples) is preferred. Note that this is the simplest possible setting—making the constraints nonlinear, increasing the dimensionality, introducing noise, etc… all make online learning preferred. - Online learning is conceptually harder, and hence more researchable. The essential difficulty is that there is no well defined static global optima, as exists for many other optimization-based learning algorithms. Grappling with this lack is of critical importance.
Nikunj C. Oza wrote an interesting paper on online bagging and boosting: pdf. (also see his PhD-Thesis: pdf ).
The algorithm has also been successfully used for various vision-tasks:
1
2
Online Parallel Boosting:
http://www.anncbt.org/papers/OnlineParallelBoosting_POCA_AAAI04_Reichler.pdf
from From Proceedings of the Nineteenth National Conference on Artificial Intelligence (AAAI-04), 2004
john: can you define online learning? my internal definition is that an learning algorithm is online if it makes predictions on each element before seeing the label, and is evaluated in terms of its performance on these elements. (plus there is often not a distribution assumption, but an adversary assumption.)
in that case, it’s unclear what all of the elements in your list mean (online svms, online DTs, etc), since SVMs and DTs are not really online problems.
The definition of online learning is a bit confused. Online SVMs, DTs, etc… mostly refers to the online optimization definition of online learning rather thant he learning-with-an-adversary definition. Of course, such theory is also quite interesting.
I think it depends on what you mean by Online SVM: there are indeed online SVMs (like the NORMA algorithm) that can be understood in the learning-with-an-adversary definition. In fact, all the “online svms” I know have that property….
What you describe sounds like adaptive learning: you “adapt” after feedback for each example.
Online to me means that you handle each training example one at a time.
can you please give me source code of “online boosting”