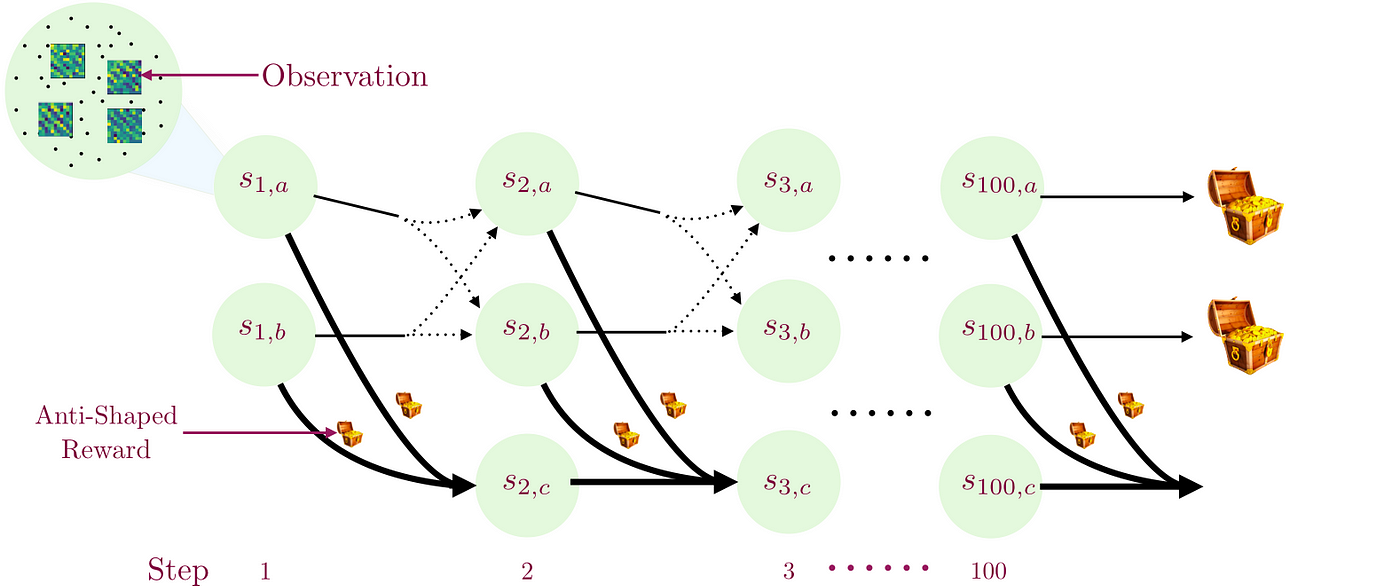
(Dylan Foster and Alex Lamb both helped in creating this.)
In thinking about what are good research problems, it’s sometimes helpful to switch from what is understood to what is clearly possible. This encourages us to think beyond simply improving the existing system. For example, we have seen instances throughout the history of machine learning where researchers have argued for fixing an architecture and using it for short-term success, ignoring potential for long-term disruption. As an example, the speech recognition community spent decades focusing on Hidden Markov Models at the expense of other architectures, before eventually being disrupted by advancements in deep learning. Support Vector Machines were disrupted by deep learning, and convolutional neural networks were displaced by transformers. This pattern may repeat for the current transformer/large language model (LLM) paradigm. Here are some quick calculations suggesting it may be possible to do significantly better along multiple axes. Examples include the following:
- Language learning efficiency: A human baby can learn a good model for human language after observing 0.01% of the language tokens typically used to train a large language model.
- Representational efficiency: A tiny Portia spider with a brain a million times smaller than a human can plan a course of action and execute it over the course of an hour to catch prey.
- Long-term planning and memory: A squirrel caches nuts and returns to them after months of experience, which would correspond to keeping billions of visual tokens in context using current techniques.
The core of this argument is that it is manifestly viable to do better along multiple axes, including sample efficiency and the ability to perform complex tasks requiring memory. All these examples highlight advanced capabilities that can be achieved at scales well below what is required by existing transformer architectures and training methodologies (in terms of either data or compute). This is in no way meant as an attack on transformer architectures; they are a highly disruptive technology, accomplishing what other types of architectures have not, and they will likely serve as a foundation for further advances. However, there is much more to do.
Next, we delve into each of the examples above in greater detail.
Sample complexity: The language learning efficiency gap
The sample efficiency gap is perhaps best illustrated by considering the core problem of language modeling where a transformer is trained to learn language. A human baby starts with no appreciable language but learns it well before adulthood. Reading at 300 words per second with 1.3 tokens/word on average implies 6.5 tokens/second. Speaking is typically about half of reading speed, implying three tokens per second. Sleeping and many other daily activities of course involve no tokens per second. Overall, one language token per second is a reasonable rough estimate of what a child observes. At this rate, 31 years must pass before they observe a billion tokens. Yet speculations about GPT-4 suggest four orders of magnitude more than a human observes in the process of learning. Closing this language learning efficiency gap (or more generally, sample efficiency gap) can have significant impact at multiple scales:
- Large models: Organizations have already scraped most of the internet and exhausted natural sources for high-quality tokens (e.g., arXiv, Wikipedia). To continue improving the largest models, better sample efficiency may be required.
- Small models: In spite of significant advances, further improvements to sample efficiency may be required if we want small language models (e.g., at the 3B scale) to reach the same level of performance as frontier models like GPT-4.
There are common arguments against the existence of a language efficiency gap which appear unconvincing.
Maybe a better choice of tokens is all you need?
This can’t be entirely ruled out, but the Phi series was an effort in this direction with the latest model trained on 10T tokens, implying there’s still a four-orders-of-magnitude efficiency gap between a human and a model which is still generally weaker than GPT-4 along most axes. It is possible that more sophisticated interactive data collection approaches could help close this gap, but this is largely unexplored.
Maybe language learning is evolutionary?
The chimpanzee-human split is estimated to have occurred between 5M and 13M years ago, resulting in a 35 million base-pair difference. The timeline for the appearance of language is estimated to have occurred between 2.5M and 150K years ago. Estimating divergence at 10M years ago and language occurring 1M years ago, with a stable rate of evolution on both sides. This suggests a crude upper bound of 35M/10/2 = 1.75M base pairs (or, around 3.5M bits) on the number of DNA bits encoding language inheritance. That’s around 5 orders of magnitude less than the number of parameters in a modern LLM, so this is not a viable explanation for the language efficiency gap.
On the other hand, it could be the case that the evolutionary lineage of humans evolved most language precursors long before actual language. The human genome has about 3.1B base pairs, with about one-third of proteins primarily expressed in the brain. Using an estimate of 1B base pairs (around 2B bits) that are brain related. This is still around two orders of magnitude smaller than the LLMs in use today, so it’s not a viable explanation for the language learning efficiency gap. It is plausible that the structure of neurons in a human brain, which strongly favors sparse connections over the dense connections favored by a GPU, are advantageous for learning purposes.
Maybe human language learning is accelerated by multimodality?
Humans benefit from a rich sensory world, notably through visual perception, which extends far beyond language. Estimating a “token count” for this additional information is difficult, however. For example, if someone is reading a book at 6.5 tokens per second, are they benefiting from all the extra sensory information? A recent paper puts the rate at which information is consciously processed in a human brain at effectively 10 bits/second which is only modestly more than the cross entropy of a language model. More generously, we could work from the common saying that “a picture is worth a thousand words” which is not radically different from techniques for encoding images into transformers. Using this, we could estimate that extra modalities increase the number of tokens by three orders of magnitude, resulting in 1T tokens observed by age 31. Given this, there is still an order-of-magnitude learning efficiency gap between humans and language models of the same class as GPT-4.
Maybe the learning efficiency gap does not matter?
In some domains, it may be possible to overcome the inefficiencies of a learning architecture by simply gathering more and more data as needed. At a scientific level, this is not a compelling argument, since understanding the fundamental limits of what is possible is the core purpose of science. Hence, this is a business argument, which may indeed be valid in some cases. A business response is that learning efficiency matters in domains where it is difficult or impossible to collect sufficient data: think of robot demonstrations, personalizing models, problems with long range structure, a universal translator encountering a new language, and so on. In addition, improving learning efficiency may lead to improvement in other forms of efficiency (e.g., memory and compute) via architectural improvements.
Model size: The representational efficiency gap
A second direction in which transformer-based models can be improved lies in model size, or representational efficiency. This is perhaps best illustrated by considering the problem of designing models or agents capable of physical or animal-like intelligence. This includes capabilities like 1) understanding one’s environment (perception); 2) moving oneself around (locomotion); and 3) planning to reach goals or accomplish basic tasks (e.g., navigation and manipulation). Naturally, this is very relevant if our goal is to build foundation models for embodied decision making.
The Portia spider has a brain one million times smaller than that of a human, yet it is observed to plan a course of action and execute it successfully over durations as long as an hour. Stated another way, it is possible to engage in significant physical intelligence behavior with 100M floats representing the neural connections and a modest gigaflop CPU capable of executing them in real time. This provides a strong case that much animal intelligence can be radically more representationally efficient than what has been observed in lingual domains, or yet implemented in software. A concrete question along these lines is:
Can we design a model with 100M floats that can effectively navigate and accomplish physical-intelligence tasks in the real world?
It is not clear whether there is an existing model of any size that can effectively do this. The most famous examples in this direction are game agents, which only function in relatively simple environments.
Are transformer models for language representationally inefficient?
While the discussion above concerns representational efficiency for physical intelligence, it is also interesting to consider representational efficiency for language. That is, are existing language models representationally efficient, or can similar capabilities be achieved with substantially smaller models? On the one hand, it is possible that language is an inherently complex process to both produce and understand. On the other hand, it might be possible to represent human level language in a radically more size-efficient manner, as in the case of physical intelligence.
To this end, one interesting example is given by Alex, a grey parrot that managed to learn and meaningfully use a modest vocabulary with a brain one-hundredth the size of a human brain by weight. If we accept the computational model of a neuron as a nonlinearity on a linear integration, Alex might have 1B neurons operating at 1T flops. Given Alex’s limited language ability, this isn’t constraining enough to decisively argue that language models that are substantially smaller than current models can be achieved. At the same time, it is plausible that most of Alex’s brain was not devoted to human language, offering some hope.
The long-term memory and planning gap
A third direction concerns developing models and agents suitable for domains that involve complex long-term interactions, which may necessitate the following capabilities:
Memory: Effectively summarizing the history of interaction into a succinct representation and using it in context.
Planning: Choosing the next actions or tokens deliberately to achieve a long range goal.
Recent advances like O1 and R1 handle relatively short range planning but are significant advancements in this vein. Existing applications of transformer language models largely avoid long-term interactions, since they can deviate from instructions. To highlight why we might expect to improve this situation, note that humans manage to engage in coherent plans over years-long timescales. Human-level intelligence isn’t required for this, though, as many animals exhibit behaviors that require long-timescale memory and planning. For example, a squirrel with a brain less than one-hundredth the size of a human brain stores food and reliably comes back to it after months of experience. Restated in a transformer-relevant way, a squirrel can experience billions of intervening (and potentially distracting) visual tokens before recalling the location of a cache of food and returning to it. How can we develop competitive models and agents with this capability?
Does it matter?
A common approach to circumvent memory and planning limitations of existing models is to create an outer-level executor that uses the LLM as a subroutine, combined with other tools for memory or planning systems. These approaches tacitly acknowledges the limits of current architectures by offering an alternative solution. Historically, as for machine vision or speech recognition, it has always been more difficult to create a learning system that accomplishes the task of interest with end-to-end training, but it was worthwhile when done as the results were superior. This pattern may repeat for long-term memory and planning, yielding better solutions.