This problem has been cracked (but not quite completely solved) by Alina, Pradeep, and I. The problem is essentially finding a better way to reduce multiclass classification to binary classification. The solution is to use a carefully crafted tournament, the simplest version of which is a single elimination tournament where the “players” are the different classes. An example of the structure is here:
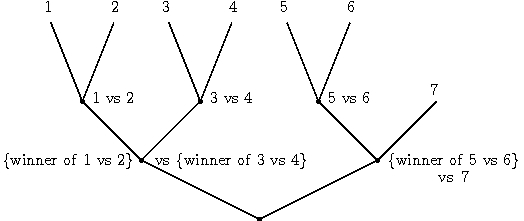
For the single elimination tournament, we can prove that:
Here:
- Filter_tree_train(D) is the induced binary classification problem
- Filter_tree_test(c) is the induced multiclass classifier.
- regmulticlass is the multiclass regret (= difference between error rate and minimum possible error rate)
- regbinary is the binary regret
This result has a slight dependence on k which we suspect is removable. The current conjecture is that this dependence can be removed by using higher order tournaments such as double elimination, triple elimination, up to log2 k-elimination.
The key insight which makes the result possible is conditionally defining the prediction problems at interior nodes. In essence, we use the learned classifiers from the first level of the tree to filter the distribution over examples reaching the second level of the tree. This process repeats, until the root node is reached. Further details, including a more precise description and some experimental results are in the draft paper.