Last week at ICML 2020, Mikael Henaff, Akshay Krishnamurthy, John Langford and I had a paper on a new reinforcement learning (RL) algorithm that solves three key problems in RL: (i) global exploration, (ii) decoding latent dynamics, and (iii) optimizing a given reward function. Our ICML poster is here.
The paper is a bit mathematically heavy in nature so this post is an attempt to distill the key findings. We will also be following up soon with a new codebase release (more on it later).
Rich-observation RL landscape
Consider the combination lock problem shown below. The agent starts in the state s1a or s1b with equal probability. After taking h-1 actions, the agent will be in either state sha, shb, or shc. The agent can take 10 different actions. The agent observes a high-dimensional observation (focus circle) instead of the underlying state which is latent. There is a big treasure chest that one can get after taking 100 actions. We view the states with subscript “a” or “b” as “good states” and one with subscript “c” as “bad states”. You can reach the treasure chest at the end only if you remain in good states. If you reach any bad state, then you can never make it to the treasure chest.
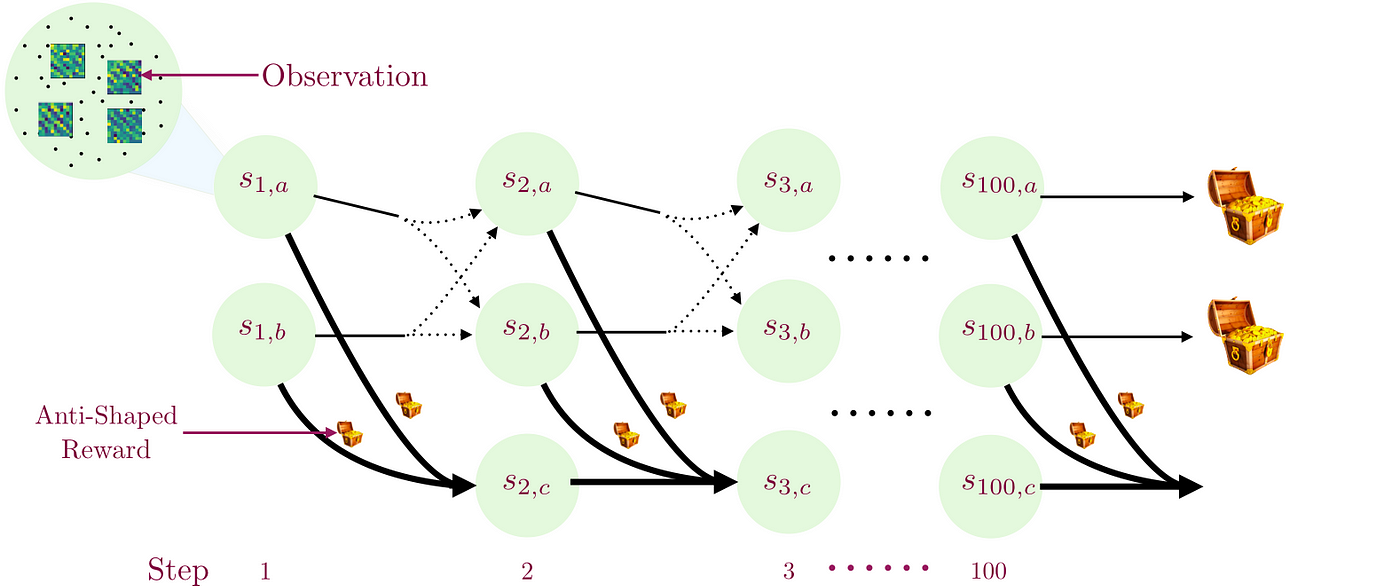
The environment makes it difficult to reach the big treasure chest in three ways. First, the environmental dynamics are such that if you are in good states, then only 1 out of 10 possible actions will let you reach the two good states at the next time step with equal probability (the good action changes from state to state). Every other action in good states and all actions in bad states put you into bad states at the next time step, from which it is impossible to recover. Second, it misleads myopic agents by giving a small bonus for transitioning from a good state to a bad state (small treasure chest). This means that a locally optimal policy is transitions to one of the bad states as quickly as possible. Third, the agent never directly observes which state it is in. Instead, it receives a high-dimensional, noisy observation from which it must decode the true underlying state.
It is easy to see that if we take actions uniformly at random, then the probability of reaching the big treasure chest at the end is 1/10100. The number 10100 is called Googol and is larger than the current estimate of number of elementary particles in the universe. Furthermore, since transitions are stochastic one can show that no fixed sequence of actions performs well either.
A key aspect of the rich-observation setting is that the agent receives observations instead of latent state. The observations are stochastically sampled from an infinitely large space conditioned on the state. However, observations are rich-enough to enable decoding the latent state which generates them.
What does provable RL mean?
A provable RL algorithm means that for any given numbers e, d in (0, 1); we can learn an e-optimal policy with probability at least 1-d using a number of episodes which are polynomial in relevant quantities (state size, horizon, action space, 1/e, 1/d, etc.). By e-optimal policy we mean a policy whose value (expected total return) is at most e less than the optimal return.
Thus, a provable RL algorithm is capable of learning a close to optimal policy with high probability (where the word high and close can be made arbitrarily more refined), provided the assumptions it makes are satisfied.
Why should I care if my algorithm is provable?
There are two main advantages of being able to show your algorithm is provable:
- We can only test an algorithm on a finite number of environments (in practice somewhere between 1 and 20). Without guarantees, we don’t know how they will behave in a new environment. This matters especially if failure in a new environment can result in high real-world costs (e.g., in health or financial domains).
- If a provable algorithm fails to consistently give the desired result, this can be attributed to failure of at least one of its assumptions. A developer can then look at the assumptions and try to determine which ones are violated, and either intervene to fix them or determine that the algorithm is not appropriate for the problem.
HOMER
Our algorithm addresses what is known as the Block MDP setting. In this setting, a small number of discrete states generates a potentially infinite number of high dimensional observations.
For each time step, HOMER learns a state decoder function, and a set of exploration policies. The state decoder maps high-dimensional observations to a small set of possible latent states, while the exploration policies map observations to actions which will lead the agent to each of the latent states. We describe HOMER below.
- For a given time step, we first learn a decoder for mapping observations to a small set of values using contrastive learning. This procedure works as follows: collect a transition by following a randomly sampled exploration policy from the previous time step until that time step, and then taking a single random action. We use this procedure to sample two transitions shown below.
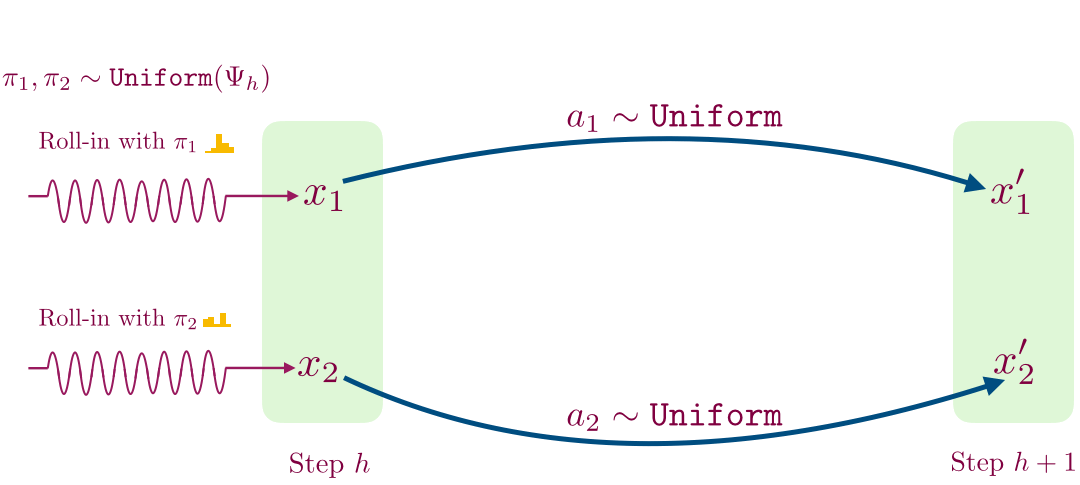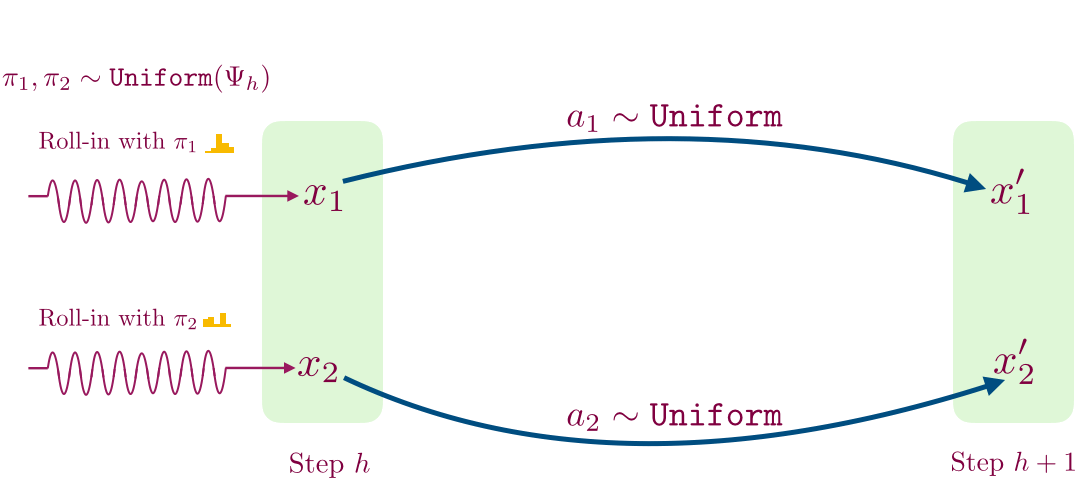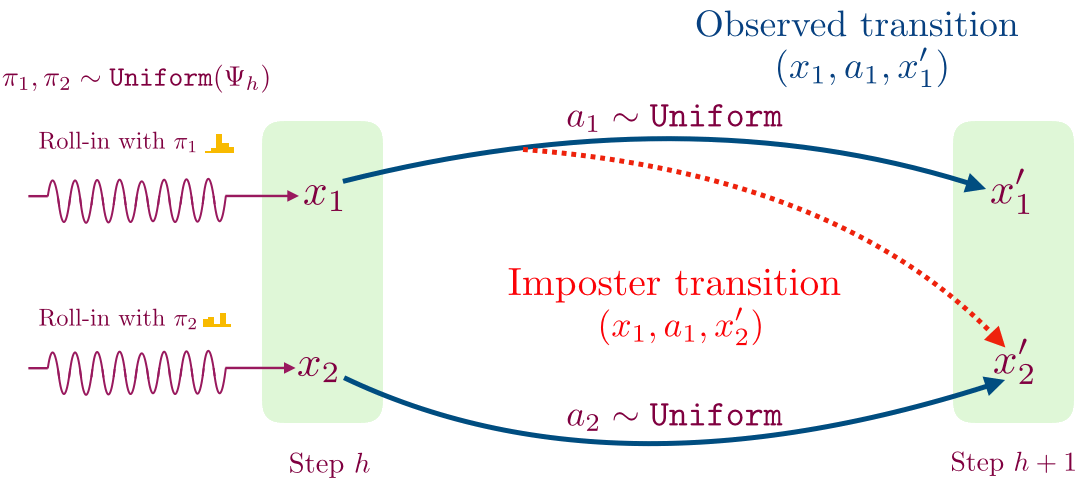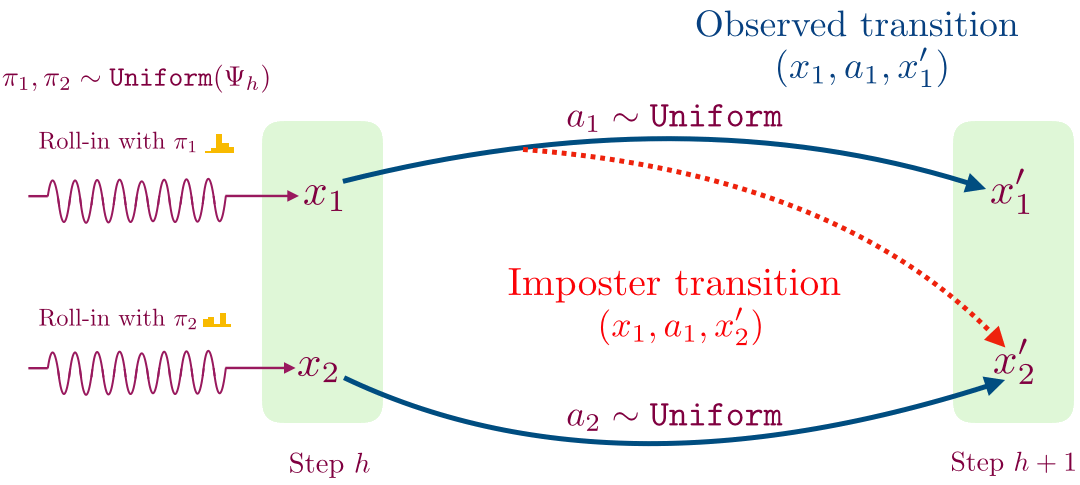
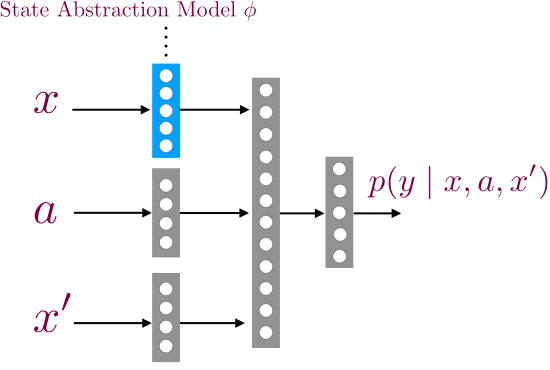
- We then flip a coin; if we get heads then we store the transition (x1, a1, x’1), and otherwise we store the imposter transition (x1, a1, x’2). We train a supervised classifier to predict if a given transition (x, a, x’) is real or not.
This classifier has a special structure which allows us to recover a decoder for time step h.
- Once we have learned the state decoder, we will learn an exploration policy for every possible value of the decoder (which we call abstract state as they are related to the latent state space). This step is standard can be done using many different approaches such as model-based planning, model-free methods, etc. In the paper we use an existing model-free algorithm called policy search by dynamic programming (PSDP) by Bagnell et al. 2004.
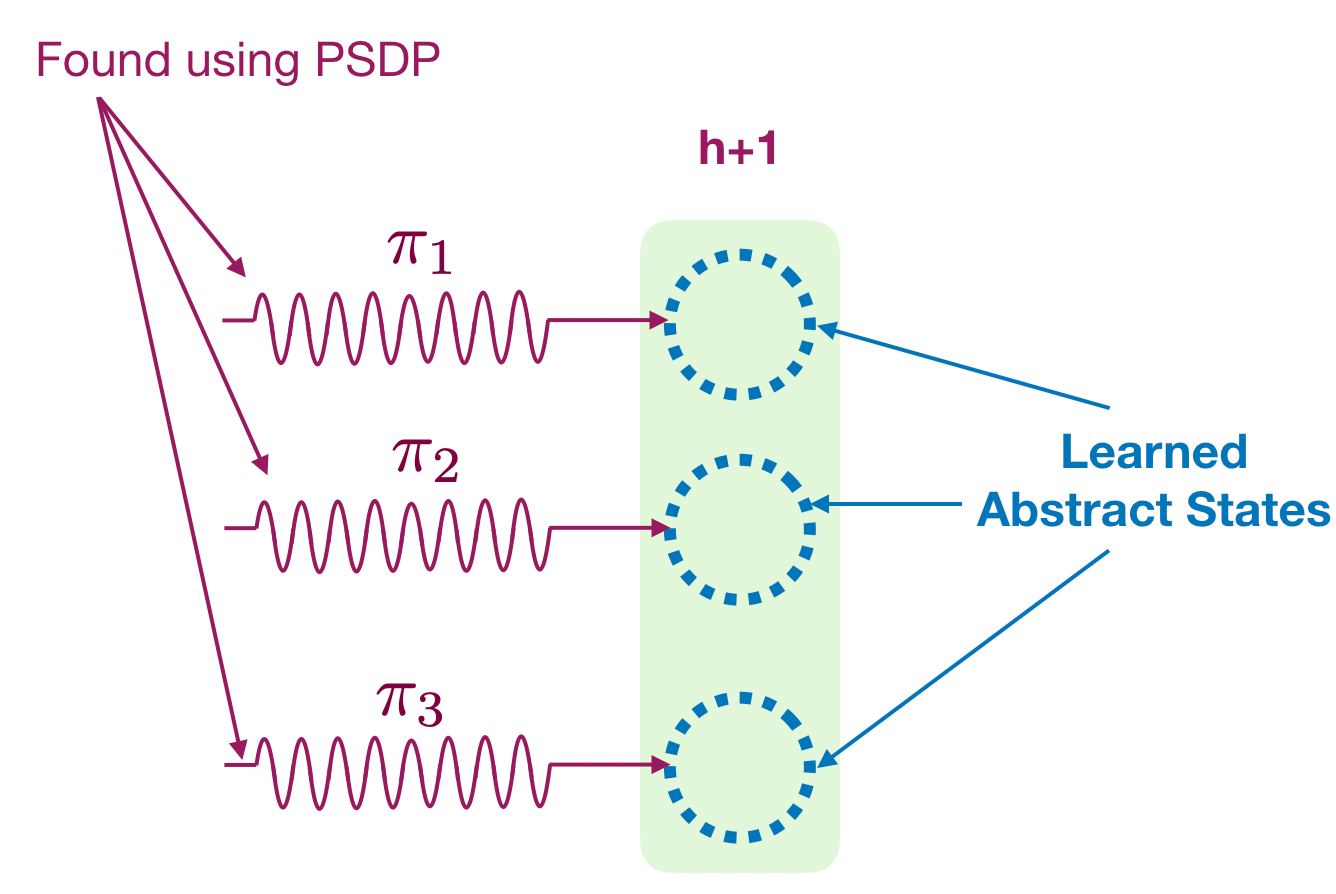
- We recovered a decoder and a set of exploration policy for this time step. We then keep doing it for every time step and learn a decoder and exploration policy for the whole latent state space. Finally, we can easily optimize any given reward function using any provable planner like PSDP or a model-based algorithm. (The algorithm actually recovers the latent state space up to an inherent ambiguity by combining two different decoders; but I’ll leave that to avoid overloading this post).
Key findings
HOMER achieves the following three properties:
- The contrastive learning procedure gives us the right state decoding (we recover up to some inherent ambiguity but I won’t cover it here).
- HOMER can learn a set of exploration policies to reach every latent state
- HOMER can learn a nearly-optimal policy for any given reward function with high probability. Further, this can be done after exploration part has been performed.
Failure cases of prior RL algorithms
There are many RL algorithms in the literature and many new are proposed every month. It is difficult to do justice to this vast literature in a blog post. It is equally difficult to situate HOMER in this vast literature. However, we show that several very commonly used RL algorithms fail to solve the above problem while HOMER succeeds. One of these is the PPO algorithm, a widely used policy gradient algorithm. In spite of its popular use, PPO is not designed for challenging exploration problems and easily fails. Researchers have made efforts to alleviate this with ad-hoc proposals such as using prediction errors, counts based on auto-encoders, etc. The best alternative approach we found is called Random Network Distillation(RND) which measures novelty of a state based on prediction errors for a fixed randomly initialized network.
Below we show how PPO+RND fails to solve the above problem while HOMER succeeds. We simplify the problem by using a grid pattern where rows represent the state (the top two represents “good” states and bottom row represents “bad” states), and column represents timestep.
We present counter-examples for other algorithms in the paper (see Section 6 here). These counterexamples allow us to find limits of prior work without expensive empirical computation on many domains.
How can I use with HOMER?
We will be providing the code soon as part of a new package release called cereb-rl. You can find it here: https://github.com/cereb-rl and join the discussion here: https://gitter.im/cereb-rl