A Cover Tree is a datastructure helpful in calculating the nearest neighbor of points given only a metric. A cover tree is particularly motivating for a confluence of reasons:
|
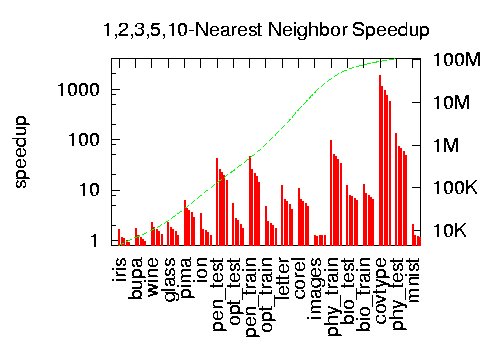
| Speedup of a cover tree over an optimized brute force approach for querying 1,2,3,5, and 10 (euclidean) nearest neighbors on a collection of datasets. |
|
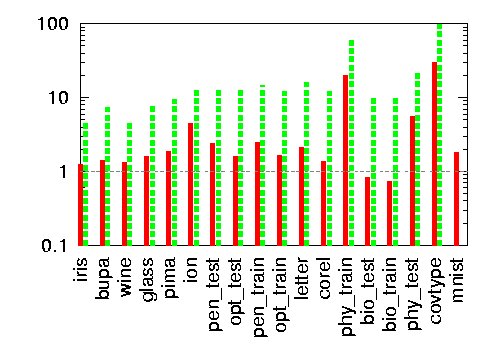
| Speedup of a cover tree over the sb(S) datastructure for querying 1,2 (euclidean) nearest neighbors |
|
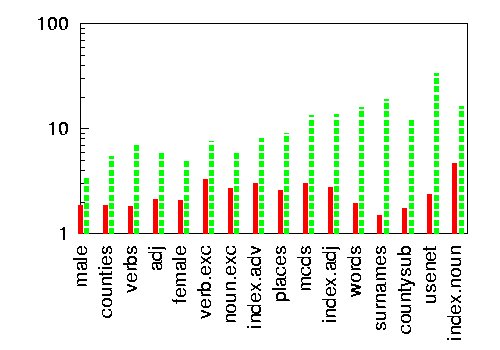
| Speedup of a cover tree over the sb(S) datastructure for querying 1,2 (string) nearest neighbors |