|
|
Progressive validation is a technique which allows you to use almost of the data in a holdout set for training purposes while still providing the same guarantee as the holdout bound. It first appeared in [3] and is discussed in a more refined and detailed form here.
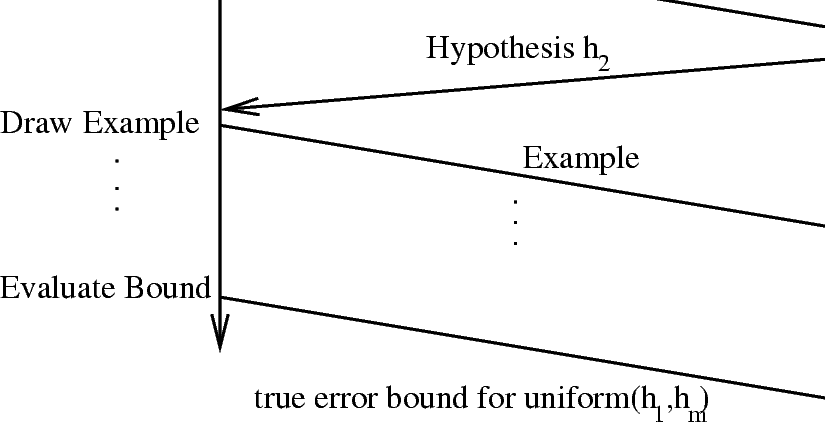
Suppose that you have a training set of size and test set of size . Progressive validation starts by first learning a hypothesis on the training set and then testing on the first example of the test set. Then, we train on training set plus the first example of the test set and test on the second example of the test set. The process continues iterations. Let abbreviate . Then, we have hypotheses, and error observations, . The hypothesis output by progressive validation is the randomized hypothesis which chooses uniformly from and evaluates to get an estimated output. Note that this protocol is similar to those in [36] and the new thing here is an analysis of performance.
Since we are randomizing over hypotheses trained on to examples, the expected number of examples used by any hypothesis is . Given that training can exhibit phase transitions, the extra few examples can greatly improve the accuracy of the trained example.
Viewed as an interactive proof of learning, the progressive validation technique follows the protocol of figure 10.1.1.
The true error rate of this randomized hypothesis will be: where and the empirical error estimate of this randomized hypothesis will be: