At NIPS I’m giving a tutorial on Learning to Interact. In essence this is about dealing with causality in a contextual bandit framework. Relative to previous tutorials, I’ll be covering several new results that changed my understanding of the nature of the problem. Note that Judea Pearl and Elias Bareinboim have a tutorial on causality. This might appear similar, but is quite different in practice. Pearl and Bareinboim’s tutorial will be about the general concepts while mine will be about total mastery of the simplest nontrivial case, including code. Luckily, they have the right order. I recommend going to both 🙂
I also just released version 7.4 of Vowpal Wabbit. When I was a frustrated learning theorist, I did not understand why people were not using learning reductions to solve problems. I’ve been slowly discovering why with VW, and addressing the issues. One of the issues is that machine learning itself was not automatic enough, while another is that creating a very low overhead process for doing learning reductions is vitally important. These have been addressed well enough that we are starting to see compelling results. Various changes:
- The internal learning reduction interface has been substantially improved. It’s now pretty easy to write new learning reduction. binary.cc provides a good example. This is a very simple reduction which just binarizes the prediction. More improvements are coming, but this is good enough that other people have started contributing reductions.
- Zhen Qin had a very productive internship with Vaclav Petricek at eharmony resulting in several systemic modifications and some new reductions, including:
- A direct hash inversion implementation for use in debugging.
- A holdout system which takes over for progressive validation when multiple passes over data are used. This keeps the printouts ‘honest’.
- An online bootstrap mechanism system which efficiently provides some understanding of prediction variations and which can sometimes effectively trade computational time for increased accuracy via ensembling. This will be discussed at the biglearn workshop at NIPS.
- A top-k reduction which chooses the top-k of any set of base instances.
- Hal Daume has a new implementation of Searn (and Dagger, the codes are unified) which makes structured prediction solutions far more natural. He has optimized this quite thoroughly (exercising the reduction stack in the process), resulting in this pretty graph.
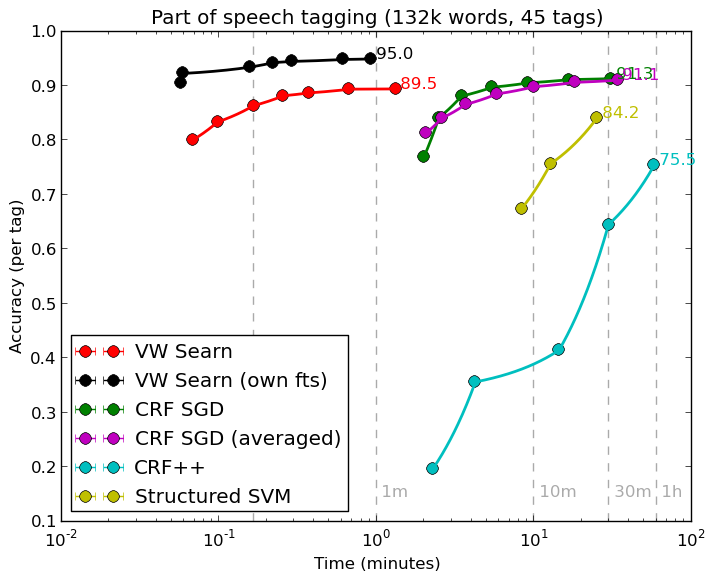
Here, CRF++ is commonly used conditional random field code, SVMstruct is an SVM-style approach to classification, and CRF SGD is an online learning CRF approach. All of these methods use the same features. Fully optimized code is typically rough, but this one is less than 100 lines.
I’m trying to put together a tutorial on these things at NIPS during the workshop break on the 9th and will add details as that resolves for those interested enough to skip out on skiing 🙂
Edit: The VW tutorial will take place during the break at the big learning workshop from 1:30pm – 3pm at Harveys Emerald Bay B.
Sounds like a major release! Any chance you’ll post the tutorial?
Yep. It was videotaped and the slides will be up as soon as I get a chance to breath.